URGENT 2024 Challenge
URGENT 2024 (Universality, Robustness, and Generalizability for EnhancemeNT) is a speech enhancement challenge accepted by the NeurIPS 2024 Competition Track. We aim to build universal speech enhancement models for unifying speech processing in a wide variety of conditions.
Goal
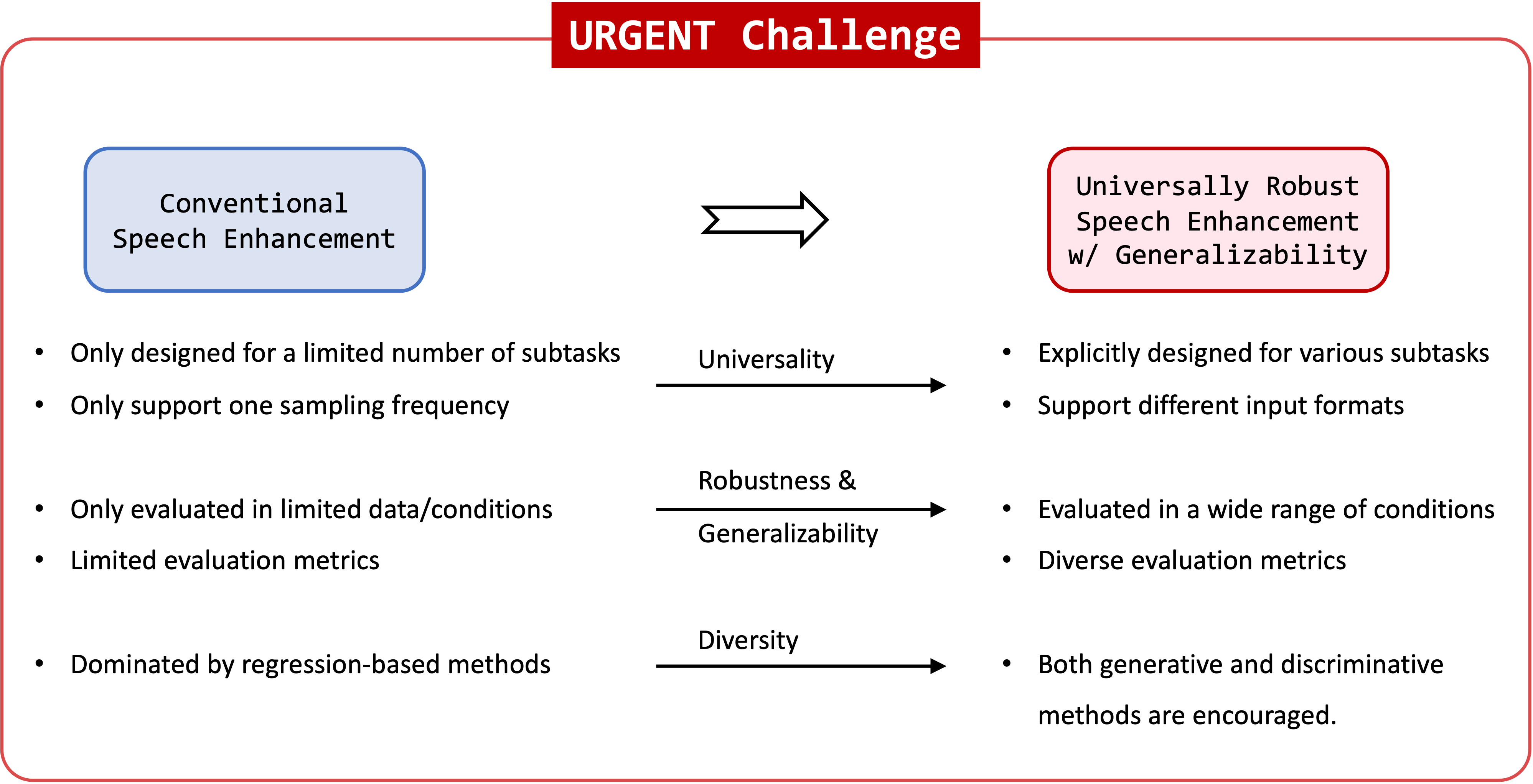
Based on the increasing interest in the generalizability of speech enhancement models, we propose the URGENT Challenge that aims to:
- Bring more attention to constructing universal speech enhancement models with strong generalizability.
- Push forward the progress of speech enhancement research towards more realistic scenarios with a comprehensive evaluation.
- Provide insightful and systematic comparison between SOTA discriminative and generative methods in a wide range of conditions, including different distortions and input formats (sampling frequencies and number of microphones).
- Provide a benchmark for this direction so that researchers can easily compare different methods.
- Allow conclusiveness of method comparisons by providing a set of training data that is exclusive and mandatory for all models.
Task Introduction
The task of this challenge is to build a single speech enhancement system to adaptively handle input speech with different distortions (corresponding to different SE subtasks) and different input formats (e.g., sampling frequencies) in different acoustic environments (e.g., noise and reverberation).
The training data will consist of several public corpora of speech, noise, and RIRs. Only the specified set of data can be used during the challenge. We encourage participants to apply data augmentation techniques such as dynamic mixing to achieve the best generalizability. The data preparation scripts are released in our GitHub repositoryData tab for more information.
We also provide baselines in the ESPnet toolkit to facilitate the system development. Check the Baseline tab for more information.
We will evaluate enhanced audios with a variety of metrics to comprehensively understand the capacity of existing generative and discriminative methods. They include four different categories of metrics
- non-intrusive metrics (e.g., DNSMOS, NISQA) for reference-free speech quality evaluation.
- intrusive metrics (e.g., PESQ, STOI, SDR, MCD) for objective speech quality evaluation.
- downstream-task-independent metrics (e.g., Levenshtein phone similarity) for language-independent, speaker-independent, and task-independent evaluation.
- downstream-task-dependent metrics (e.g., speaker similarity, word accuracy or WAcc) for evaluation of compatibility with different downstream tasks.
More details about the evaluation plan can be found in the Rules tab.
Communication
Join our Slack workspace for real-time communication.
Workshop
Top-ranking teams will be invited to a dedicated workshop in the NeurIPS 2024 conference (December 14 or December 15, 2024). More information will be provided after the challenge is completed.
Motivation
Recent decades have witnessed rapid development of deep learning-based speech enhancement (SE) techniques, with impressive performance in matched conditions. However, most conventional speech enhancement approaches focus only on a limited range of conditions, such as single-channel, multi-channel, anechoic, and so on.
In many existing works, researchers tend to only train SE models on one or two common datasets, such as the VoiceBank+DEMAND
The evaluation is often done only on simulated conditions that are similar to the training setting. Meanwhile, in earlier SE challenges such DNS series, the choice of training data was also often left to the participants. This led to the situation that models trained with a huge amount of private data were compared to models trained with a small public dataset. This greatly impedes understanding of the generalizability and robustness of SE methods comprehensively. In addition, the model design may be biased towards a specific limited condition if only a small amount of data is used. The resultant SE model may also have limited capacity to handle more complicated scenarios.
Apart from conventional discriminative methods, generative methods have also attracted much attention in recent years. They are good at handling different distortions with a single model
Meanwhile, recent efforts
Existing speech enhancement challenges have fostered the development of speech enhancement models for specific conditions, such as denoising and dereverberation
Similar issues can also be observed in other speech tasks such as automatic speech recognition (ASR), speech translation (ST), speaker verification (SV), and spoken language understanding (SLU).
Among them, speech enhancement is particularly vulnerable to mismatches since it is heavily reliant on paired clean/noisy speech data to achieve strong performance. Unsupervised speech enhancement that does not require groundtruth clean speech has been proposed to address this issue, but often merely brings benefit in a final finetuning stage