Baseline
Basic Framework
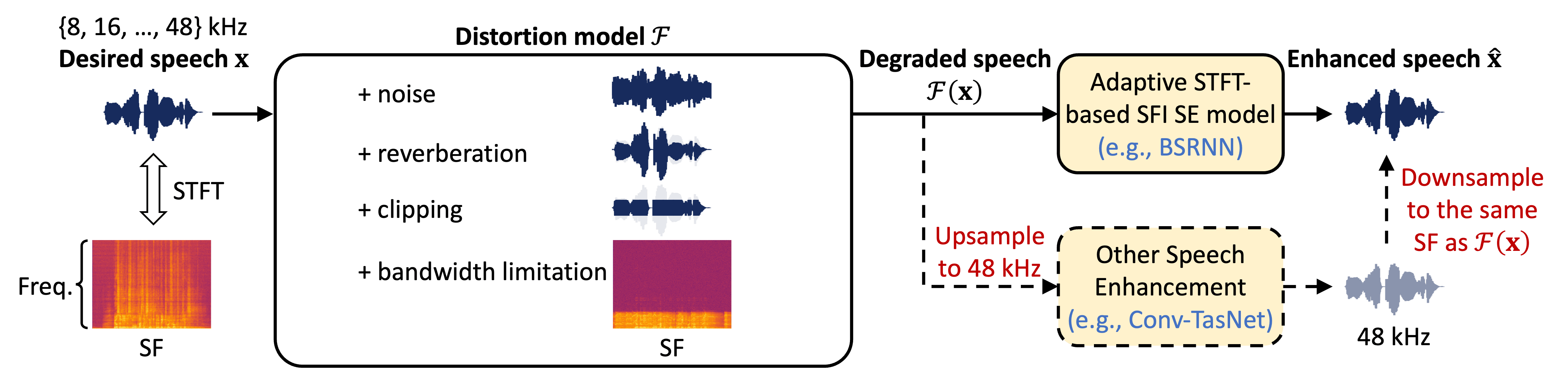
The basic framework is detailed in the challenge description paper
As depicted in the figure above, we design a distortion model (simulation stage)
During training and inference, the processing of different SFs is supported for both conventional SE models (lower-right) that usually only operate at one SF and adaptive STFT-based sampling-frequency-independent (SFI) SE models (upper-right) that can directly handle different SFs.
- For conventional SE models (e.g., Conv-TasNet
), we always upsample its input (degraded speech) to the highest SF (48 kHz) so that the model only need to operate at 48 kHz. The model output (48 kHz) is then downsampled to the same SF as the degraded speech. - For adaptive STFT-based SFI
SE models (e.g., BSRNN , TF-GridNet ), we directly feed the degraded speech of different SFs into the model, which can adaptively adjust their STFT/iSTFT configuration according to the SF and generate the enhanced signal with the same SF.
Baselines in ESPnet
We provide offical baselines and the corresponding recipe (egs2/urgent24/enh1) in the ESPnet toolkit.
To install the ESPnet toolkit for model training, please follow the instructions at https://espnet.github.io/espnet/installation.html.
You can check “A quick tutorial on how to use ESPnet” to have a quick overview on how to use ESPnet for speech enhancement.
- For the basic usage of this toolkit, please refer to egs2/TEMPLATE/enh1/README.md.
- Several baseline models are provided in the format of a
YAMLconfiguration file inegs2/urgent24/enh1/conf/tuning/.- The pretrained TF-GridNet model using the provided config can be downloaded from HuggingFace 🤗.
- To run a recipe, you basically only need to execute the following command after installing ESPnet from source:
For explanation of the arugments in./run.sh, please refer toegs2/TEMPLATE/enh1/enh.sh.cd <espnet-path>/egs2/urgent24/enh1
# data preparation (this will clone the challenge repository) ./run.sh --stage 1 --stop-stage 1 mkdir -p dump cp -r data dump/raw ./run.sh --stage 5 --stop-stage 5 --nj 8
# training ./run.sh --stage 6 --stop-stage 6 --ngpu 4 --enh_config conf/tuning/<your-favorite-config.yaml>
# inference (for both validation and test sets) ./run.sh --stage 7 --stop-stage 7 --enh_config conf/tuning/<your-favorite-config.yaml> \ --inference_nj 8 --gpu_inference true
# scoring (only for the validation set) . ./path.sh exp="exp/enh_train_enh_bsrnn_medium_noncausal_raw" # replace this with your exp directory for x in "validation"; do # non-intrusive metric (DNSMOS) python urgent2024_challenge/evaluation_metrics/calculate_nonintrusive_dnsmos.py \ --inf_scp ${exp}/enhanced_${x}/spk1.scp \ --output_dir ${exp}/enhanced_${x}/scoring_dnsmos \ --device cuda \ --convert_to_torch True \ --primary_model urgent2024_challenge/DNSMOS/DNSMOS/sig_bak_ovr.onnx \ --p808_model urgent2024_challenge/DNSMOS/DNSMOS/model_v8.onnx # non-intrusive metric (NISQA) python urgent2024_challenge/evaluation_metrics/calculate_nonintrusive_nisqa.py \ --inf_scp ${exp}/enhanced_${x}/spk1.scp \ --output_dir ${exp}/enhanced_${x}/scoring_dnsmos \ --device cuda \ --nisqa_model urgent2024_challenge/lib/NISQA/weights/nisqa.tar
# intrusive SE metrics (calculated on CPU) python urgent2024_challenge/evaluation_metrics/calculate_intrusive_se_metrics.py \ --ref_scp dump/raw/${x}/spk1.scp \ --inf_scp ${exp}/enhanced_${x}/spk1.scp \ --output_dir ${exp}/enhanced_${x}/scoring \ --nj 8 \ --chunksize 500
# downstream-task-independent metric (SpeechBERTScore) python urgent2024_challenge/evaluation_metrics/calculate_speechbert_score.py \ --ref_scp dump/raw/${x}/spk1.scp \ --inf_scp ${exp}/enhanced_${x}/spk1.scp \ --output_dir ${exp}/enhanced_${x}/scoring_speech_bert_score \ --device cuda # downstream-task-independent metric (LPS) python urgent2024_challenge/evaluation_metrics/calculate_phoneme_similarity.py \ --ref_scp dump/raw/${x}/spk1.scp \ --inf_scp ${exp}/enhanced_${x}/spk1.scp \ --output_dir ${exp}/enhanced_${x}/scoring_phoneme_similarity \ --device cuda
# downstream-task-dependent metric (SpkSim) python urgent2024_challenge/evaluation_metrics/calculate_speaker_similarity.py \ --ref_scp dump/raw/${x}/spk1.scp \ --inf_scp ${exp}/enhanced_${x}/spk1.scp \ --output_dir ${exp}/enhanced_${x}/scoring_speaker_similarity \ --device cuda # downstream-task-dependent metric (WER or 1-WAcc) python urgent2024_challenge/evaluation_metrics/calculate_wer.py \ --meta_tsv dump/raw/${x}/text \ --inf_scp ${exp}/enhanced_${x}/spk1.scp \ --output_dir ${exp}/enhanced_${x}/scoring_wer \ --device cuda done
The average scores will be written respectively in ${exp}/enhanced_${x}/scoring*/RESULTS.txt.