Track1: Universal Speech Enhancement
Contents:
Datasets
🆕 [Nov. 3 Update] Blind Test for Leaderboard Now Available
The blind test set is now available at urgent26_track1_blind_test.
-
Please refer to the submission guide and upload your enhanced speech results to the leaderboard for blind test evaluation (opens after Nov. 4).
-
The blind test set contains 360 simulated samples and 480 real-world samples collected from public sources.
-
It includes five previously unseen languages beyond those used in the training data.
⚠️ Note: The blind test ranking follows a two-stage evaluation. The top-6 systems from
stage 1(objective metrics) will advance tostage 2for subjective testing. POLQA scores are not computed in real time and are therefore excluded from regular leaderboard updates. However, POLQA will be incorporated into the finalstage 1ranking for the top-6 systems. As a result, the final leaderboard (should be published separately after the evaluation) may differ from the real-time leaderboard shown during submission.
Non-Blind Test for Leaderboard
🆕 The non-blind test set with reference audio and labels is available here.
Notice: ⚠️ A simulation-related Issue has been corrected in the baseline code. It is recommended that you pull the latest code from the baseline repository to ensure proper dynamic simulation behavior. Some noisy files contain complete silence due to this bug in the earlier simulation version. However, the official validation set that we release remains unchanged to preserve leaderboard consistency. The official validation is for dry-run use only and does not affect final ranking.
The non-blind test is available at urgent26_track1_nonblind_test
- Check the submission guide, and submit the enhanced speech to the leaderboard for the non-blind test (opens after Oct. 14).
- The non-blind test was simulated in the same way as the official validation set, but it includes a richer variety of speeches.
After the non-blind test phase ends, clean speech and metadata will be available.
Official Validation Set for Leaderboard Testing
The official validation set with reference audio and labels is available here.
To help participants get familiar with the leaderboard submission process, we provide an official validation set:
- Download it here: urgent26_track1_leaderboard_validation
- For dry-run submissions before non-blind/blind test sets
- Ranked using the same objective metrics as final evaluation (stage 1).
- Check the submission guide first, and the leaderboard for validation will open after Sept. 21.
This set is not for training. Use it to verify your submission format and preview leaderboard ranking.
Brief data description:
The training and validation data are both simulated by using several public speech/noise/rir corpora (see the table below for more details). We provide the data preparation pipeline with the official baseline, which automatically downloads and pre-processes the data.
Non-blind/bind test set will be released later, check the timeline page for more details.
Detailed data description:
Based on the dataset of the 2nd URGENT challenge, we conducted a data selection using the data filtering method proposed in a recent paper
It is noted that we encourage you to explore better ways of data selection and utilization in this challenge. In addition to the data and filtering methods provided by our baseline, you can make use of larger-scale datasets, such as the track1/track2 data from the 2nd URGENT challenge, or other allowed data (please check it in the rules section).
The training and validation data are both simulated based on the following source data.
| Type | Corpus | Condition | Sampling Frequency (kHz) | Duration of in 2nd URGENT | Duration of in 3rd URGENT | License |
|---|---|---|---|---|---|---|
| Speech | LibriVox data from DNS5 challenge | Audiobook | 8~48 | ~350 h | ~150 h | CC BY 4.0 |
| LibriTTS reading speech | Audiobook | 8~24 | ~200 h | ~109 h | CC BY 4.0 | |
| VCTK reading speech | Newspaper, etc. | 48 | ~80 h | ~44 h | ODC-BY | |
| EARS speech | Studio recording | 48 | ~100 h | ~16 h | CC-NC 4.0 | |
| Multilingual Librispeech (de, en, es, fr) | Audiobook | 8~48 | ~450 (48600) h | ~129 h | CC0 | |
| CommonVoice 19.0 (de, en, es, fr, zh-CN) | Crowd-sourced voices | 8~48 | ~1300 (9500) h | ~250 h | CC0 | |
| NNCES | Children speech | 44.1 | - | ~20 h | CC0 | |
| SeniorTalk | Elderly speech | 16 | - | ~50 h | CC BY-NC-SA 4.0 | |
| VocalSet | Singing voice | 44.1 | - | ~10 h | CC BY 4.0 | |
| ESD | Emotional speech | 16 | - | ~30 h | non-commercial, custom |
For the noise source and RIRs, we follow the same configuration as in the 2nd URGENT challenge.
| Type | Corpus | Condition | Sampling Frequency (kHz) | Duration of in 2nd URGENT | License |
|---|---|---|---|---|---|
| Noise | Audioset+FreeSound noise in DNS5 challenge | Crowd-sourced + Youtube | 8~48 | ~180 h | CC BY 4.0 |
| WHAM! noise | 4 Urban environments | 48 | ~70 h | CC BY-NC 4.0 | |
| FSD50K (human voice filtered) | Crowd-sourced | 8~48 | ~100 h | CC0, CC-BY, CC-BY-NC, CC Sampling+ | |
| Free Music Archive (medium) | Free Music Archive (directed by WFMU) | 8~44.1 | ~200 h | CC | |
| Wind noise simulated by participants | - | any | - | N/A | |
| RIR | Simulated RIRs from DNS5 challenge | SLR28 | 48 | ~60k samples | CC BY 4.0 |
| RIRs simulated by participants | - | any | - | N/A |
Participants can also simulate their own RIRs using existing tools for generating the training data. Participants can also propose publicly available, real recorded RIRs to be included in the above data list during the grace period. See rules section for more details.
Data selection and Simulation. We apply the data selection to the track1 data of the 2nd URGENT using the data filtering method proposed in the recent paper
Note that the data filtering of paper
The simulation data can be generated as follows:
-
In the first step, a manifest
meta.tsvis first generated bysimulation/generate_data_param.pyfrom the given list of speech, noise, and room impulse response (RIR) samples. It specifies how each sample will be simulated, including the type of distortion to be applied, the speech/noise/RIR sample to be used, the signal-to-noise ratio (SNR), the random seed, and so on. -
In the second step, the simulation can be done in parallel via
simulation/simulate_data_from_param.pyfor different samples according to the manifest while ensuring reproducibility. This procedure can be used to generate training and validation datasets. -
By default, we applied a high-pass filter to the speech signals since we have noticed that there is high-energy noise in the infrasound frequency band in some speech sources. You can turn it off by setting
highpass=Falsein your simulation.
A pre-simulated training and validation dataset
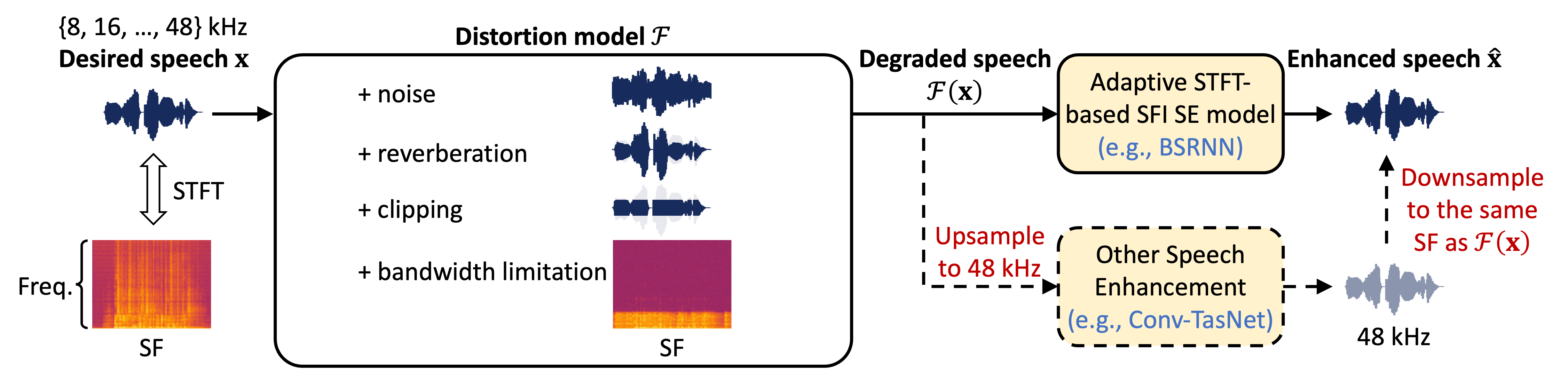
Distortions Model. As depicted in the figure above, we design a distortion model (simulation stage)
During training and inference, the processing of different SFs is supported for both conventional SE models (lower-right) that usually only operate at one SF and adaptive STFT-based sampling-frequency-independent (SFI) SE models (upper-right) that can directly handle different SFs.
- For conventional SE models (e.g., Conv-TasNet
), we always upsample its input (degraded speech) to the highest SF (48 kHz) so that the model only needs to operate at 48 kHz. The model output (48 kHz) is then downsampled to the same SF as the degraded speech. - For adaptive STFT-based SFI
SE models (e.g., BSRNN , TF-GridNet ), we directly feed the degraded speech of different SFs into the model, which can adaptively adjust their STFT/iSTFT configuration according to the SF and generate the enhanced signal with the same SF.
In the challenge, the SE system has to address the following seven distortions:
- Additive noise
- Reverberation
- Clipping
- Bandwidth limitation
- Codec distortion
- Packet loss
- Wind noise
We provide an example simulation script as simulation/simulate_data_from_param.py.
Baseline
Please refer to the official GitHub repository for more details.
Discriminative Baseline. We provide an adaptive STFT-based SFI
Generative Baseline. We follow a recent work named FlowSE
Rules
-
When generating the training and validation datasets, ONLY the speech, noise, and room impulse response (RIR) corpora listed in the Datasets section shall be used to ensure a fair comparison and proper understanding of various SE approaches.
-
The first month of the challenge will be a grace period when participants can propose additional public datasets to be included in the list. We (organizers) will reply to the requests and may update the list. Updates will be recorded in the
Noticetab. - It is NOT allowed to use pre-trained speech enhancement models trained on other than official Challenge data.
- However, it IS allowed to use a pre-trained model trained on the official challenge data (e.g., URGENT 2024 / URGENT 2025 / URGENT 2026 official baseline )
- Although the speech enhancement model should only be trained on the listed data, we allow the use of pre-trained foundation models such as HuBERT, WavLM, EnCodec, Llama, and so on. We also allow the use of a pretrained speech enhancement/restoration model to improve the quality of clean speech for simulation. The use of all pre-trained models must meet the following requirements:
- They are publicly available before the challenge begins
- They are explicitly mentioned in the submitted system description.
- Note:
- Their parameters can be fine-tuned on the listed data.
- It is not allowed to fine-tune any model, be it pre-trained or not, on any extra data other than the listed data.
- If you are unsure whether the pre-trained model you would like to use is allowed, please reach out to the organizers.
-
- We allow participants to simulate their own RIRs using existing tools
For example, RIR-Generator, pyroomacoustics, gpuRIR, and so on. for generating the training data. The participants can also propose publicly available, real recorded RIRs to be included in the above data list during the grace period (SeeTimeline).Note: If participants used additional RIRs to train their model, the related information should be provided in the README.yaml file in the submission. Check the template for more information.
-
We allow participants to simulate wind noise using some tools such as SC-Wind-Noise-Generator. In default, the simulation script in our repository simulates 200 and 100 wind noises for training and validation for each sampling frequency. The configuration can be easily changed in wind_noise_simulation_train.yaml and wind_noise_simulation_validation.yaml
-
The test data should only be used for evaluation purposes. Techniques such as test-time adaptation, unsupervised domain adaptation, and self-training on the test data are NOT allowed.
-
There is no constraint on the latency or causality of the developed system in this challenge. Any type of model can be used as long as it conforms to the other rules as listed on this page.
- Registration is required to submit results to the challenge (Check
How to Participatefor more information). Note that the team information (including affiliation, team name, and team members) should be provided when submitting the results. For detailed submission requirements, please check theSubmissionpart.- Only the team name will be shown in the leaderboard, while the affiliation and team members will be kept confidential.
- Only the team name will be shown in the leaderboard, while the affiliation and team members will be kept confidential.
Submission
- Please read the following guidelines first, and then submit your results here.
- Each submission should be a zip file containing two parts:
- enhanced audios corresponding to the subset to be tested;
- a YAML (README.yaml) file containing the basic information about the submission (as listed below). The template can be found here.
- team information (team name, affiliation, team mambers)
- description of the training & validation data used for the submission
- description of pre-trained models used for the submission (if applicable)
- The zip file should only contain a single YAML (README.yaml) file and a folder named
enhancedthat contains all the enhanced audio files. That is, the directory structure after executingunzip {your_teamname}.zipshould be as follows:
./
├── README.yaml
└── enhanced/
├── fileid_1.flac
├── fileid_2.flac
├── ...
└── fileid_N.flac
- Note that the submission without README.yaml is rejected by the leaderboard system.
- Please encode all audio files in the 16-bit FLAC format to reduce the file size (< 300 MB).
- The audio files should be encoded in mono-channel with its original sampling frequency.
- All audio files should have the same name and length as the original audio files in the provided subset to be tested.
- Be careful not to include hidden directories in the zip file such as
__MACOSX/which may cause evaluation failure. - The submission should be done via our official leaderboard website:
- A registration (please sign up at https://urgent-challenge.com) is required to participate in our challenge.
- Each team shall only register once. Multiple registrations from different members in one team are not allowed.
- Each team can submit up to 2 submissions per day during the challenge.
- The third and later submissions will be ignored. The quota will be reset at 00:00 (UTC timezone) every day.
- Failed submissions are not taken into account when counting the submissions per day.
- No submission will be accepted after the deadline (January 15th, 2025).
- For each team, only the submission with the best leaderboard performance will be used for the final evaluation.
Submissions that fail to conform to the above requirements may be rejected.
Should you encounter any problem during the submission, please feel free to contact the organizers.
By submitting the results, the participants agree to the following conditions:
As a condition of submission, entrants grant the organizers, a perpetual,
irrevocable, worldwide, royalty-free, and non-exclusive license to use,
reproduce, adapt, modify, publish, distribute, publicly perform, create a
derivative work from, and publicly display the submitted audio signals and
CSV files (containing the performance scores).
The main motivation for this condition is to donate the submitted audio
signals and corresponding performance scores to the community as a
voice quality dataset.
Ranking
The blind test ranking will be carried out in two stages. In stage 1, we will evaluate participants’ submissions with multiple objective metrics. The top-6 systems in the objective overall ranking will advance to the stage 2, be evaluated by multiple subjective tests, and then the final ranking will be determined by the subjective overall ranking. For the validation set and non-blind test set, the leardboard will only rank with the multiple objective metrics.
-
The following objective evaluation metrics will be calculated for evaluation in
stage 1. For real recorded test samples that do not have a strictly matched reference signal, part of the following metrics will be used. Theoverall rankingwill be determined by the algorithm introduced in the subsequent section.Category Metric Need Reference Signals? Non-intrusive SE metrics DNSMOS ↑ ❌ NISQA ↑ ❌ UTMOS ↑ ❌ SCOREQ ↑ ❌ Intrusive SE metrics POLQA This metric will only be used for evaluation of the final blind test set. ↑✔ PESQ ↑ ✔ ESTOI ↑ ✔ Downstream-task-independent metrics SpeechBERTScore To evaluate multilingual speech, we adopt the MHuBERT-147 backend for calculating the SpeechBERTScore, which differs from its default backend (WavLM-Large). ↑✔ LPS ↑ ✔ Downstream-task-dependent metrics Speaker Similarity ↑ ✔ Emotion Similarity ↑ ✔ Language identification accuracy ↑ ❌ Character accuracy (1 - CER) ↑ ❌ -
In
stage 2, we will make ITU-T P.808 Absolute Category Rating (ACR) and Comparison Category Rating (CCR) for the top-6 submissions, and the Mean Opinion Score (MOS) and Comparison Mean Opinion Score (CMOS) will be used for subjective metric ranking. Then theoverall rankingin the subjective evaluation will become thefinal rankingof the challenge. It is noted that, if theoverall rankingsof the subjective tests of two teams are the same, we will refer to theoverall rankingsof the objective tests to determine thefinal rankings.Category Metric Evaluation method Subjective metrics MOS ↑ ITU-T P.808 ACR CMOS ↑ ITU-T P.808 CCR
Overall ranking method
The overall ranking will be determined via the following procedure:
- Calculate the
average scoreof each metric for each submission. - Calculate the
per-metric rankingbased on the average score.- We adopt the dense ranking (“1223” ranking)
https://en.wikipedia.org/wiki/Ranking#Dense_ranking_("1223"_ranking) strategy for handling ties.
- We adopt the dense ranking (“1223” ranking)
- Calculate the
per-category rankingby averaging the rankings within each category. - Calculate the
overall rankingby averaging theper-category rankings.
# Step 1: Calculate the average score of each metric
scores = {}
for submission in all_submissions:
scores[submission] = {}
for category in metric_categories:
for metric in category:
scores[submission][metric] = mean([metric(each_sample) for each_sample in submission])
# Step 2: Calculate the per-metric ranking based on the average score
rank_per_metric = {}
rank_per_category = {}
for category in metric_categories:
for metric in category:
rank_per_metric[metric] = get_ranking([scores[submission][metric] for submission in all_submissions])
# Step 3: Calculate the `per-category ranking` by averaging the rankings within each category
rank_per_category[category] = get_ranking([rank_per_metric[metric] for metric in category])
# Step 4: Calculate the overall ranking by averaging the `per-category rankings`
rank_overall = get_ranking([rank_per_category[category] for category in metric_categories])