Baseline
🚧 This website is currently under construction. All content is subject to change and may not reflect the final details of the competition. Please refer to official announcements once the contest begins for the most accurate and up-to-date information.
Baseline code and checkpoint
Please refer to the official GitHub repository for more details.
Distortion model
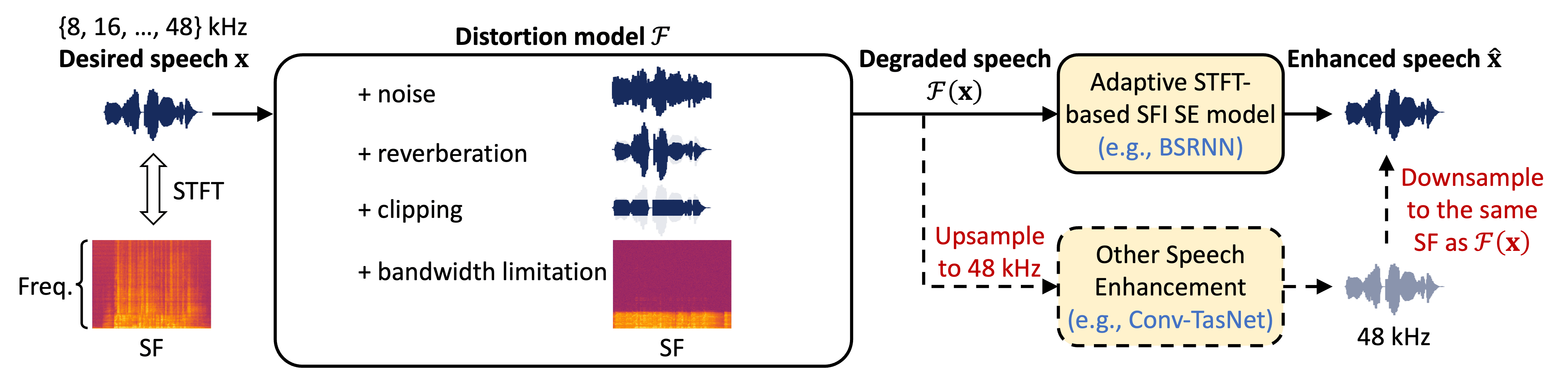
As depicted in the figure above, we design a distortion model (simulation stage)
During training and inference, the processing of different SFs is supported for both conventional SE models (lower-right) that usually only operate at one SF and adaptive STFT-based sampling-frequency-independent (SFI) SE models (upper-right) that can directly handle different SFs.
- For conventional SE models (e.g., Conv-TasNet
), we always upsample its input (degraded speech) to the highest SF (48 kHz) so that the model only needs to operate at 48 kHz. The model output (48 kHz) is then downsampled to the same SF as the degraded speech. - For adaptive STFT-based SFI
SE models (e.g., BSRNN , TF-GridNet ), we directly feed the degraded speech of different SFs into the model, which can adaptively adjust their STFT/iSTFT configuration according to the SF and generate the enhanced signal with the same SF.
Discriminative Baseline
We provide an adaptive STFT-based SFI
Generative Baseline
We follow a recent work named FlowSE